数据库的并发控制的概念
什么是并发控制
参考资料 浅谈数据库并发控制 - 锁和 MVCC
学习 Java 时也知道解决资源共享问题最简单粗暴方法就是给对应资源操作上加上 synchronized 关键字,从而让多个线程操作这个资源时进行排队拿锁(其实更接近 AQS)而这种阻塞的方式就是串行化,在 Java 这种本身就在内存中执行的语言,其实速度还是很快的,但是到了数据库这里,它的操作都是直接面向硬盘的,如果还是使用串行那就实在有点过分了,而并发控制机制就是数据库在 并发性能 和 可串行化 之间做的权衡和妥协
如果数据库中的所有事务都是串行执行的,那么它非常容易成为整个应用的性能瓶颈,虽然说没法水平扩展的节点在最后都会成为瓶颈,但是串行执行事务的数据库会加速这一过程;而并发(Concurrency)使一切事情的发生都有了可能,它能够解决一定的性能问题,但是它会带来更多诡异的错误。(具体看事务隔离级别那篇遇到的问题)
而最为常见的三种并发控制机制:分别是悲观并发控制(悲观锁)、乐观并发控制(乐观锁)和多版本并发控制(MVCC)

悲观并发控制
控制不同的事务对同一份数据的获取是保证数据库的一致性的最根本方法,如果我们能够让事务在同一时间对同一资源有着独占的能力,那么就可以保证操作同一资源的不同事务不会相互影响。
最简单的、应用最广的方法就是使用锁来解决,当事务需要对资源进行操作时需要先获得资源对应的锁,保证其他事务不会访问该资源后,在对资源进行各种操作;
在悲观并发控制中,数据库程序对于数据被修改持悲观的态度,在数据处理的过程中都会被锁定,以此来解决竞争的问题。
读写锁
为了最大化数据库事务的并发能力,数据库中的锁被设计为两种模式,分别是共享锁(ReadLock)和排它锁(WriteLock)。
当一个事务获得共享锁之后,它只可以进行读操作,所以共享锁也叫读锁; 而当一个事务获得一行数据的互斥锁时,就可以对该行数据进行读和写操作,所以互斥锁也叫写锁。
这里拿 Java 的读写锁介绍来解释了
共享锁(ReadLock):也称读锁或 S锁。如果事务对数据 A 加上共享锁后,则其他事务只能对 A 再加共享锁,不能加排它锁。获准共享锁的事务只能读数据,不能修改数据。在 Java 中的 ReentrantReadWriteLock 也是如此。
Java 中共享锁是指该锁可被多个线程所持有。如果线程 T 对数据 A 加上共享锁后,则其他线程只能对 A 再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
排它锁(WriteLock):也称独占锁、写锁或 X锁。如果事务对数据 A 加上排它锁后,则其他事务不能再对 A 加任何类型的锁。获得排它锁的事务即能读数据又能修改数据。
Java 中排他锁是指该锁一次只能被一个线程所持有。如果线程 T 对数据 A 加上排它锁后,则其他线程不能再对 A 加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK 中的 synchronized 和 JUC 中 Lock 的实现类就是互斥锁。
一次封锁 or 两段锁?
参考资料 Innodb中的事务隔离级别和锁的关系
因为有大量的并发访问,为了预防死锁,一般应用中推荐使用一次封锁法,就是在方法的开始阶段,已经预先知道会用到哪些数据,然后全部锁住,在方法运行之后,再全部解锁。这种方式可以有效的避免循环死锁,但在数据库中却不适用,因为在事务开始阶段,数据库并不知道会用到哪些数据。
数据库遵循的是两段锁协议,将事务分成两个阶段,加锁阶段和解锁阶段(所以叫两段锁)
加锁阶段:在该阶段可以进行加锁操作。在对任何数据进行读操作之前要申请并获得 S锁(共享锁,其它事务可以继续加共享锁,但不能加排它锁),在进行写操作之前要申请并获得 X锁(排它锁,其它事务不能再获得任何锁)。加锁不成功,则事务进入等待状态,直到加锁成功才继续执行。
解锁阶段:当事务释放了一个封锁以后,事务进入解锁阶段,在该阶段只能进行解锁操作不能再进行加锁操作。
| 事务 | 加锁/解锁处理 |
|---|---|
| begin; | |
| insert into test….. | 加 insert 对应的锁 |
| update test set… | 加 update 对应的锁 |
| delete from test…. | 加 delete 对应的锁 |
| commit; | 事务提交时,同时释放 insert、update、delete 对应的锁 |
这种方式虽然无法避免死锁,但是两段锁协议可以保证事务的并发调度是串行化(串行化很重要,尤其是在数据恢复和备份的时候)的。
两阶段锁协议
两阶段锁协议(2PL)是一种能够保证事务可串行化的协议,它将事务的获取锁和释放锁划分成了增长(Growing)和缩减(Shrinking)两个不同的阶段。
- 在增长阶段,一个事务可以获得锁但是不能释放锁;
- 而在缩减阶段事务只可以释放锁,并不能获得新的锁
它还有两个变种:
- Strict 2PL:事务持有的互斥锁必须在提交后再释放;
- Rigorous 2PL:事务持有的所有锁必须在提交后释放;
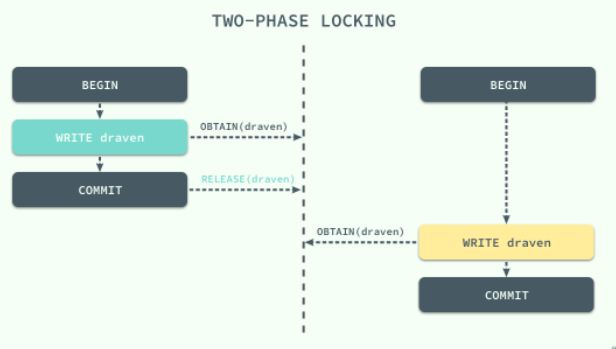
如下图可见,当左边的事务拿到锁后,右边的事务必须得等左边事务执行完后才能执行写操作(这里的 draven 和 beacon 只是资源名称,别想那么多)
虽然锁的使用能够为我们解决不同事务之间由于并发执行造成的问题,但是两阶段锁的使用却引入了另一个严重的问题,死锁;不同的事务等待对方已经锁定的资源就会造成死锁,这里举一个简单的例子:
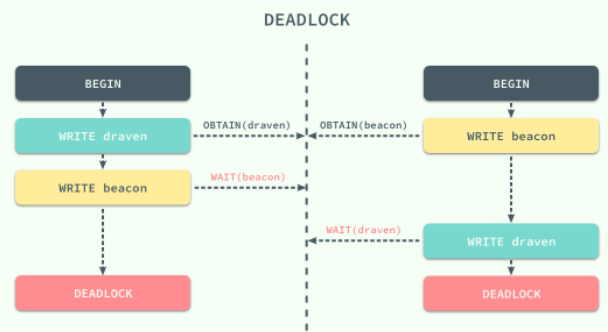
两个事务在刚开始时分别获取了 draven 和 beacon 资源上面的锁,然后再请求对方已经获得的锁时就会发生死锁,双方都没有办法等到锁的释放,如果没有死锁的处理机制就会无限等待下去,两个事务都没有办法完成。
死锁的处理
死锁在多线程编程中是经常遇到的事情,一旦涉及多个线程对资源进行争夺就需要考虑当前的几个线程或者事务是否会造成死锁;
解决死锁大体来看有两种办法,
- 一种是从源头杜绝死锁的产生和出现,
- 另一种是允许系统进入死锁的状态,但是在系统出现死锁时能够及时发现并且进行恢复。
乐观并发控制
基于时间戳的协议
锁协议按照不同事务对同一数据项请求的时间依次执行,因为后面执行的事务想要获取的数据已将被前面的事务加锁,只能等待锁的释放,所以基于锁的协议执行事务的顺序与获得锁的顺序有关。在这里想要介绍的基于时间戳的协议能够在事务执行之前先 决定事务的执行顺序。
每一个事务都会具有一个全局唯一的时间戳,它即可以使用系统的时钟时间,也可以使用计数器,只要能够保证所有的时间戳都是唯一并且是随时间递增的就可以。
基于时间戳的协议能够保证事务并行执行的顺序与事务按照时间戳串行执行的效果完全相同;每一个数据项都有两个时间戳,读时间戳和写时间戳,分别代表了当前成功执行对应操作的事务的时间戳。
该协议 能够保证所有冲突的读写操作都能按照时间戳的大小 串行执行,在执行对应的操作时不需要关注其他的事务只需要关心数据项对应时间戳的值就可以了:
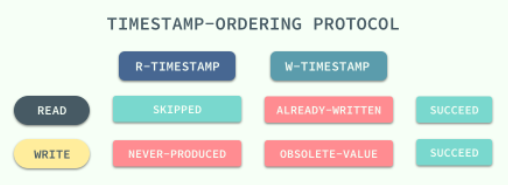
无论是读操作还是写操作都会从左到右依次比较读写时间戳的值,如果小于当前值就会直接被拒绝然后回滚,数据库系统会给回滚的事务添加一个新的时间戳并重新执行这个事务。
注:这种基于时间戳的协议算是悲观锁,乐观锁在下面(实际就是 CAS)
基于验证的协议
乐观并发控制其实本质上就是基于验证的协议,因为在多数的应用中只读的事务占了绝大多数,事务之间因为写操作造成冲突的可能非常小,也就是说 大多数的事务在不需要并发控制机制也能运行的非常好,也可以保证数据库的一致性;而并发控制机制其实向整个数据库系统添加了很多的开销,我们其实可以通过别的策略降低这部分开销。
而验证协议就是我们找到的解决办法,它根据事务的只读或者更新将所有事务的执行分为两到三个阶段:读、校验(可能进入 abort)、写
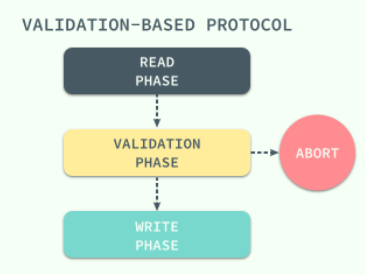
在读阶段,数据库会执行事务中的全部读操作和写操作,并将所有写后的值存入临时变量中,并不会真正更新数据库中的内容;在这时候会进入下一个阶段,数据库程序会检查当前的改动是否合法,也就是是否有其他事务在 READ PHASE 期间更新了数据,如果通过测试那么直接就进入 WRITE PHASE 将所有存在临时变量中的改动全部写入数据库,没有通过测试的事务会直接被终止。(就是 CAS 的概念)
为了保证乐观并发控制能够正常运行,我们需要知道一个事务不同阶段的发生时间,包括事务开始时间、验证阶段的开始时间以及写阶段的结束时间;通过这三个时间戳,我们可以保证任意冲突的事务不会同时写入数据库,一旦由一个事务完成了验证阶段就会立即写入,其他读取了相同数据的事务就会回滚重新执行。(实际就是结合上面的时间戳协议的概念来完成 CAS)
作为乐观的并发控制机制,它会假定所有的事务在最终都会通过验证阶段并且执行成功,而锁机制和基于时间戳排序的协议是悲观的,因为它们会在发生冲突时强制事务进行等待或者回滚,哪怕有不需要锁也能够保证事务之间不会冲突的可能。
多版本并发控制 MVCC
到目前为止我们介绍的并发控制机制其实都是通过延迟或者终止相应的事务来解决事务之间的竞争条件(Race condition)来保证事务的可串行化;
虽然前面的两种并发控制机制确实能够从根本上解决并发事务的可串行化的问题,但是在实际环境中数据库的事务大都是只读的,读请求是写请求的很多倍,如果写请求和读请求之前没有并发控制机制,那么最坏的情况也是读请求读到了已经写入的数据,这对很多应用完全是可以接受的。
在这种大前提下,数据库系统引入了另一种并发控制机制 - 多版本并发控制(Multiversion Concurrency Control),每一个写操作都会创建一个新版本的数据,读操作会从有限多个版本的数据中挑选一个最合适的结果直接返回;
在这时,读写操作之间的冲突就不再需要被关注,而管理和快速挑选数据的版本就成了 MVCC 需要解决的主要问题。
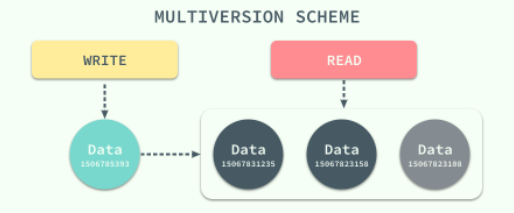
MVCC 并不是一个与乐观和悲观并发控制对立的东西,它能够与两者很好的结合以增加事务的并发量,在目前最流行的 SQL 数据库 MySQL 和 PostgreSQL 中都对 MVCC 进行了实现;但是由于它们分别实现了悲观锁和乐观锁,所以 MVCC 实现的方式也不同。
MySQL 与 MVCC
MySQL 中实现的多版本两阶段锁协议(Multiversion 2PL)将 MVCC 和 2PL 的优点结合了起来,每一个版本的数据行都具有一个唯一的时间戳,当有读事务请求时,数据库程序会直接从多个版本的数据项中具有最大时间戳的返回。

更新操作就稍微有些复杂了,事务会先读取最新版本的数据计算出数据更新后的结果,然后创建一个新版本的数据,新数据的时间戳是目前数据行的最大版本 +1:

数据版本的删除也是根据时间戳来选择的,MySQL 会将版本最低的数据定时从数据库中清除以保证不会出现大量的遗留内容。
总结 LBCC 和 MVCC
LBCC,基于锁的并发控制,Lock Based Concurrency Control
LBCC 使用锁的机制,在当前事务需要对数据修改时,将当前事务加上锁,同一个时间只允许一条事务修改当前数据,其他事务必须等待锁释放之后才可以操作。
MVCC,多版本的并发控制,Multi-Version Concurrency Control
MVCC 生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照提供一定级别(语句级或事务级)的一致性读取
使用版本来控制并发情况下的数据问题,在 B事务开始修改账户且事务未提交时,当 A事务需要读取账户余额时,此时会读取到 B事务修改操作之前的账户余额的副本数据,但是如果 A事务需要修改账户余额数据就必须要等待 B事务提交事务。
MVCC 使得数据库读不会对数据加锁,普通的 SELECT 请求不会加锁,提高了数据库的并发处理能力。 借助MVCC,数据库可以实现READ COMMITTED,REPEATABLE READ等隔离级别,用户可以查看当前数据的前一个或者前几个历史版本,保证了ACID中的I特性(隔离性)。