常用的缓存策略
常用的三种缓存淘汰(失效)算法:FIFO,LFU 和 LRU
FIFO/LFU/LRU 算法简介
缓存全部存储在内存中,内存是有限的,因此不可能无限制地添加数据。假定我们设置缓存能够使用的内存大小为 N,那么在某一个时间点,添加了某一条缓存记录之后,占用内存超过了 N,这个时候就需要从缓存中移除一条或多条数据了。那移除谁呢?我们肯定希望尽可能移除“没用”的数据,那如何判定数据“有用”还是“没用”呢?
FIFO(First In First Out)
先进先出,也就是淘汰缓存中最老(最早添加)的记录。FIFO 认为,最早添加的记录,其不再被使用的可能性比刚添加的可能性大。这种算法的实现也非常简单,创建一个队列,新增记录添加到队尾,每次内存不够时,淘汰队首。但是很多场景下,部分记录虽然是最早添加但也最常被访问,而不得不因为呆的时间太长而被淘汰。这类数据会被频繁地添加进缓存,又被淘汰出去,导致缓存命中率降低。
LFU(Least Frequently Used)
最少使用,也就是淘汰缓存中访问频率最低的记录。LFU 认为,如果数据过去被访问多次,那么将来被访问的频率也更高。LFU 的实现需要维护一个按照访问次数排序的队列,每次访问,访问次数加1,队列重新排序,淘汰时选择访问次数最少的即可。
LFU 算法的命中率是比较高的,但缺点也非常明显,维护每个记录的访问次数,对内存的消耗是很高的;另外,如果数据的访问模式发生变化,LFU 需要较长的时间去适应,也就是说 LFU 算法受历史数据的影响比较大。例如某个数据历史上访问次数奇高,但在某个时间点之后几乎不再被访问,但因为历史访问次数过高,而迟迟不能被淘汰。
LRU(Least Recently Used)
最近最少使用,相对于仅考虑时间因素的 FIFO 和仅考虑访问频率的 LFU,LRU 算法可以认为是相对平衡的一种淘汰算法。LRU 认为,如果数据最近被访问过,那么将来被访问的概率也会更高。LRU 算法的实现非常简单,维护一个队列,如果某条记录被访问了,则移动到队尾,那么队首则是最近最少访问的数据,淘汰该条记录即可。
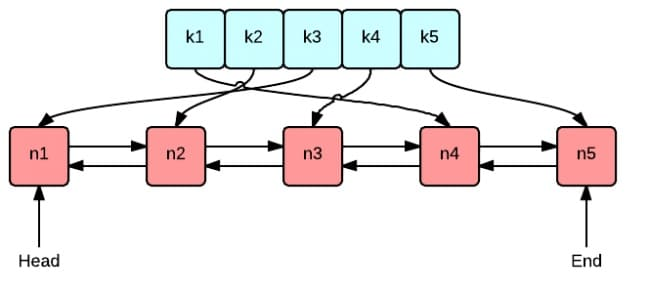
这张图很好地表示了 LRU 算法最核心的 2 个数据结构
绿色的是字典(map),存储键和值的映射关系。这样根据某个键(key)查找对应的值(value)的复杂是O(1),在字典中插入一条记录的复杂度也是O(1)。
红色的是双向链表(double linked list)实现的队列。将所有的值放到双向链表中,这样,当访问到某个值时,将其移动到队尾的复杂度是O(1),在队尾新增一条记录以及删除一条记录的复杂度均为O(1)。