微积分与深度学习的关系 微积分在深度学习中起着重要作用,它是深度学习背后数学原理的基石之一。深度学习涉及许多复杂的数学概念和运算,而微积分提供了处理这些概念和运算的工具和框架。以下是微积分与深度学习之间的一些关系:
梯度下降和优化: 深度学习中的优化算法(如梯度下降)使用了微积分的概念。梯度下降通过计算损失函数关于模型参数的梯度(导数),然后沿着梯度的反方向更新参数,从而优化模型。微积分中的导数和偏导数是梯度计算的基础。
反向传播算法: 反向传播是训练神经网络的关键技术,它通过链式法则计算梯度。这个过程依赖于微积分中的链式法则,它允许我们有效地计算复合函数的导数。
函数逼近: 深度学习模型通常是复杂的非线性函数逼近器。微积分的概念,如导数和曲线的切线,帮助我们理解和建模这些复杂的函数关系。
激活函数: 在神经网络中,激活函数引入非线性性。微积分中的导数帮助我们理解激活函数的变化率和对损失函数的影响。
积分和期望: 在某些情况下,深度学习涉及对函数的积分或期望值的计算。这涉及到微积分的积分概念。
微分方程: 深度学习也在求解微分方程和时间序列建模中发挥作用。微积分提供了解决这些问题的数学工具。
总之,微积分为深度学习提供了数学基础,使得我们能够理解、开发和优化复杂的神经网络模型。虽然不是必须要精通微积分才能进行深度学习,但对微积分的理解可以帮助深入理解深度学习的背后原理和技术。
积分是什么? 积分是数学中的一个基本概念,它表示对一个函数的某种性质在一个给定区间内的累积或总和。积分的主要目的是测量曲线下的面积,描述变化率,求解方程等。
具体来说,积分可以有不同的含义和用途,主要分为以下两种常见类型:
不定积分 :不定积分通常用于找到一个函数的原函数,也称为不定积分的结果。原函数是指一个函数的导数,因此不定积分可以看作是导数的逆运算。不定积分的结果通常包含一个常数项,因为导数无法确定原函数的常数部分。
例如,如果我们有一个函数 f ( x ) f(x) f ( x ) ∫ f ( x ) d x \int f(x) dx ∫ f ( x ) d x F ( x ) F(x) F ( x ) F ′ ( x ) = f ( x ) F'(x) = f(x) F ′ ( x ) = f ( x ) F ( x ) F(x) F ( x ) f ( x ) f(x) f ( x )
定积分 :定积分用于计算一个函数在一个特定区间内的累积效应或总和,通常表示为 ∫ a b f ( x ) d x \int_a^b f(x) dx ∫ a b f ( x ) d x a a a b b b [ a , b ] [a, b] [ a , b ]
例如,如果我们有一个函数 f ( x ) f(x) f ( x ) [ a , b ] [a, b] [ a , b ] ∫ a b f ( x ) d x \int_a^b f(x) dx ∫ a b f ( x ) d x
积分在数学中有广泛的应用,包括解决微积分问题、计算曲线下的面积、描述物理过程中的累积效应、计算概率分布下的期望值等。它是数学和科学领域中不可或缺的工具之一。
∫ \int ∫ ∑ \sum ∑ ∫ \int ∫ ∑ \sum ∑
用途 :
∫ \int ∫ ∑ \sum ∑ 数学对象 :
∫ \int ∫ ∑ \sum ∑ 总之,∫ \int ∫ ∑ \sum ∑ ∫ \int ∫ ∑ \sum ∑
求不定积分 求不定积分是找到一个函数的原函数(也称为不定积分的结果)。原函数是指一个函数的导数,因此不定积分可以看作是导数的逆运算。下面举例说明如何求不定积分以及不定积分与导数之间的关系。
考虑函数 f ( x ) = 2 x f(x) = 2x f ( x ) = 2 x ∫ f ( x ) d x \int f(x) dx ∫ f ( x ) d x
步骤 1:写出不定积分的表达式。不定积分的一般形式为 ∫ f ( x ) d x \int f(x) dx ∫ f ( x ) d x f ( x ) f(x) f ( x ) x x x
∫ 2 x d x \int 2x dx ∫ 2 x d x
步骤 2:计算不定积分。要计算这个不定积分,我们可以使用幂的不定积分公式。对于 x n x^n x n 1 n + 1 x n + 1 \frac{1}{n+1} x^{n+1} n + 1 1 x n + 1 n n n
在我们的例子中,n = 1 n = 1 n = 1
∫ 2 x d x = 2 ⋅ 1 2 x 2 + C \int 2x dx = 2 \cdot \frac{1}{2} x^{2} + C ∫ 2 x d x = 2 ⋅ 2 1 x 2 + C
步骤 3:添加常数项。不定积分结果中通常包含一个常数项 C C C
2 ⋅ 1 2 x 2 + C = x 2 + C 2 \cdot \frac{1}{2} x^{2} + C = x^{2} + C 2 ⋅ 2 1 x 2 + C = x 2 + C
所以,不定积分 ∫ 2 x d x \int 2x dx ∫ 2 x d x x 2 + C x^2 + C x 2 + C C C C
关于不定积分和导数的关系:
不定积分是导数的逆运算。如果 F ( x ) F(x) F ( x ) f ( x ) f(x) f ( x ) F ′ ( x ) = f ( x ) F'(x) = f(x) F ′ ( x ) = f ( x ) ∫ f ( x ) d x = F ( x ) + C \int f(x) dx = F(x) + C ∫ f ( x ) d x = F ( x ) + C C C C F ( x ) F(x) F ( x ) f ( x ) f(x) f ( x )
在上面的例子中,我们求得不定积分 ∫ 2 x d x = x 2 + C \int 2x dx = x^2 + C ∫ 2 x d x = x 2 + C x 2 + C x^2 + C x 2 + C 2 x 2x 2 x f ( x ) = 2 x f(x) = 2x f ( x ) = 2 x
常数 C C C
不定积分在微积分中用于解决各种问题,包括计算曲线下的面积、求解微分方程、估计累积效应等。
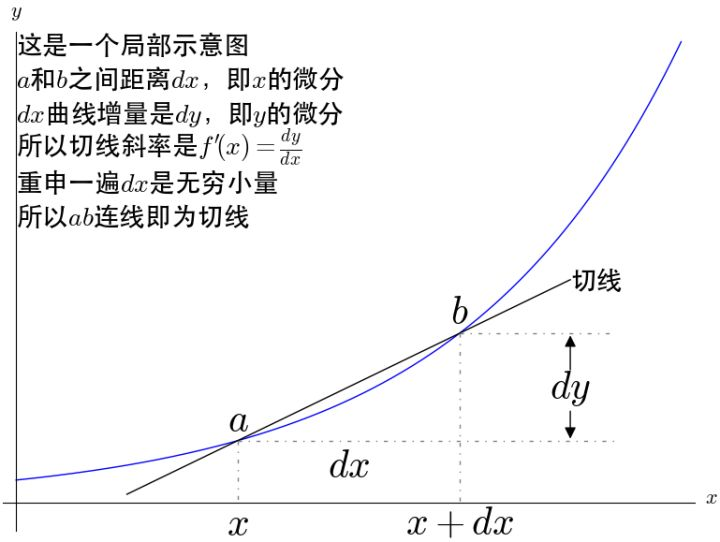
导数和微分 导数和微分都是微积分中重要的概念,用于研究函数的变化率和斜率。虽然它们经常一起出现,但它们在某些情况下有不同的含义。
快速理解版:
很多数学概念不好理解,原因有很多,其中很重要的一个是它们的汉语表达,和我们的直觉经验相差太远。
那么,如果我们把这些概念和自己的日常经验和形象直觉构建起来了一种联系,它们就好理解一些了。
从现在开始,忘了导数、微分和偏导数这三个概念。
首先引入第一个概念:变化率。
小强第一天吃1个包子,第二天吃 2 个,第三天吃 3 个,第四天吃 4 个。
那么 x 为时间,y 为包子,则构成 x = 1 , 2 , 3 , 4 x={1,2,3,4} x = 1 , 2 , 3 , 4 y = 1 , 2 , 3 , 4 y={1,2,3,4} y = 1 , 2 , 3 , 4
变化率就是包子变化的量(增量),比上时间变化的量,就是包子减包子再除以时间减时间,在这个例子里,变化率一直为1。
所以变化率就很好理解了,在这个例子里就是单位时间内的包子变化量。扩大开来,就是纵轴的变化量比上横轴的变化量。
它的函数是 y=x,那么,y=2x 呢?同理可发现变化率为2。
再引入第二个概念:最微小变化量。
假设你在游戏中操作一个英雄,他开始的战斗力为100点,你在游戏中获得了一个宝藏,打开之后,每秒钟力量增加1点,那么随着时间流逝,战斗力必将无限增加。
那么,每1秒钟增加1点,或者10秒中增加10点,都是变化量。
那么,每0.000……1秒增加了多少呢?增加了0.000……1点战斗力,这个微小的不能再微小的增加,就是最微小变化量。
再引入第三个概念:相对变化率。
假如,在这个游戏中,英雄在打开宝藏之后,又喝了战斗之水,战斗之水的变化规律是指数级变化,y=x²,喝x滴水,战斗力增长x²。
那么,这个时候,战斗力随着宝藏和战斗力共同增长,而变化,也随着宝藏赋予和战斗之水赋予,呈现出两个变化的和。
在这个情况下,如果我们假设“战斗之水”为不变参数(常数),而只把宝藏当作变化量,求宝藏带来的变化率,这个结果相对变化率。(以上是为了通俗说明,事实上举例中存在不严谨的地方。)
综上,下面我们进行改名工作——
把变化率换成导数 把最微小变化量换成微分 把相对变化率换成偏导数 导数是什么? 导数(Derivative): 导数是描述函数在某一点的变化率的概念。对于一个函数 f ( x ) f(x) f ( x ) x 0 x_0 x 0 f ′ ( x 0 ) f'(x_0) f ′ ( x 0 )
f ′ ( x 0 ) = lim h → 0 f ( x 0 + h ) − f ( x 0 ) h f'(x_0) = \lim_{h \to 0} \frac{f(x_0 + h) - f(x_0)}{h} f ′ ( x 0 ) = h → 0 lim h f ( x 0 + h ) − f ( x 0 ) 这个定义表示当我们在点 x 0 x_0 x 0 h h h f ( x ) f(x) f ( x ) h h h h h h x 0 x_0 x 0
让我们通过一个具体的例子来理解导数。考虑函数 f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2 x 0 = 2 x_0 = 2 x 0 = 2
首先,我们计算导数的极限表达式:
f ′ ( 2 ) = lim h → 0 f ( 2 + h ) − f ( 2 ) h f'(2) = \lim_{h \to 0} \frac{f(2 + h) - f(2)}{h} f ′ ( 2 ) = h → 0 lim h f ( 2 + h ) − f ( 2 ) 代入函数 f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2
f ′ ( 2 ) = lim h → 0 ( 2 + h ) 2 − 2 2 h f'(2) = \lim_{h \to 0} \frac{(2 + h)^2 - 2^2}{h} f ′ ( 2 ) = h → 0 lim h ( 2 + h ) 2 − 2 2 展开并化简:
f ′ ( 2 ) = lim h → 0 4 + 4 h + h 2 − 4 h = lim h → 0 4 h + h 2 h f'(2) = \lim_{h \to 0} \frac{4 + 4h + h^2 - 4}{h} = \lim_{h \to 0} \frac{4h + h^2}{h} f ′ ( 2 ) = h → 0 lim h 4 + 4 h + h 2 − 4 = h → 0 lim h 4 h + h 2 可以取消分子和分母中的 h h h
f ′ ( 2 ) = lim h → 0 ( 4 + h ) f'(2) = \lim_{h \to 0} (4 + h) f ′ ( 2 ) = h → 0 lim ( 4 + h ) 当 h h h 4 4 4 f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2 x 0 = 2 x_0 = 2 x 0 = 2 f ′ ( 2 ) = 4 f'(2) = 4 f ′ ( 2 ) = 4
这意味着在 x = 2 x = 2 x = 2 f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2 4 4 4
微分是什么? 微分(Differentiation): 微分是一种操作,用于计算函数的导数。
微分是微积分中的一个概念,用于描述函数在某一点的变化率。数学符号表示一个函数 f ( x ) f(x) f ( x ) x 0 x_0 x 0 f ′ ( x 0 ) f'(x_0) f ′ ( x 0 ) d y d x ∣ x = x 0 \frac{dy}{dx}\Big|_{x=x_0} d x d y ∣ ∣ x = x 0 x x x x 0 x_0 x 0 y y y
微分的计算方法取决于函数的具体形式。通常,我们使用极限的概念来计算微分。具体步骤如下:
考虑函数 f ( x ) f(x) f ( x ) 选择一个点 x 0 x_0 x 0 引入一个小的增量 h h h x x x x 0 + h x_0 + h x 0 + h x 0 x_0 x 0 计算函数在 x 0 x_0 x 0 x 0 + h x_0 + h x 0 + h f ( x 0 ) f(x_0) f ( x 0 ) f ( x 0 + h ) f(x_0 + h) f ( x 0 + h ) 计算增量比率:f ( x 0 + h ) − f ( x 0 ) h \frac{f(x_0 + h) - f(x_0)}{h} h f ( x 0 + h ) − f ( x 0 ) 当 h h h x 0 x_0 x 0 f ′ ( x 0 ) f'(x_0) f ′ ( x 0 ) 举个简单的例子,考虑函数 f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2 x = 2 x = 2 x = 2
函数:f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2 点:x 0 = 2 x_0 = 2 x 0 = 2 增量:h h h 函数值:f ( x 0 ) = f ( 2 ) = 2 2 = 4 f(x_0) = f(2) = 2^2 = 4 f ( x 0 ) = f ( 2 ) = 2 2 = 4 f ( x 0 + h ) = f ( 2 + h ) = ( 2 + h ) 2 f(x_0 + h) = f(2 + h) = (2 + h)^2 f ( x 0 + h ) = f ( 2 + h ) = ( 2 + h ) 2 增量比率:f ( 2 + h ) − f ( 2 ) h = ( 2 + h ) 2 − 4 h \frac{f(2 + h) - f(2)}{h} = \frac{(2 + h)^2 - 4}{h} h f ( 2 + h ) − f ( 2 ) = h ( 2 + h ) 2 − 4 当 h h h lim h → 0 ( 2 + h ) 2 − 4 h = lim h → 0 ( 4 + 4 h + h 2 − 4 ) = lim h → 0 ( 4 h + h 2 ) = 4 \lim_{h \to 0} \frac{(2 + h)^2 - 4}{h} = \lim_{h \to 0} (4 + 4h + h^2 - 4) = \lim_{h \to 0} (4h + h^2) = 4 h → 0 lim h ( 2 + h ) 2 − 4 = h → 0 lim ( 4 + 4 h + h 2 − 4 ) = h → 0 lim ( 4 h + h 2 ) = 4 所以,函数 f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2 x = 2 x = 2 x = 2 x x x y y y x 2 x^2 x 2
以下是一些常用函数求微分的例子,包括一阶和高阶导数:
多项式函数 :
f ( x ) = x 3 f(x) = x^3 f ( x ) = x 3 d d x [ x 3 ] = 3 x 2 \frac{d}{dx} [x^3] = 3x^2 d x d [ x 3 ] = 3 x 2 f ( x ) = 2 x 4 + 5 x 2 − 3 f(x) = 2x^4 + 5x^2 - 3 f ( x ) = 2 x 4 + 5 x 2 − 3 d d x [ 2 x 4 + 5 x 2 − 3 ] = 8 x 3 + 10 x \frac{d}{dx} [2x^4 + 5x^2 - 3] = 8x^3 + 10x d x d [ 2 x 4 + 5 x 2 − 3 ] = 8 x 3 + 10 x 指数函数 :
f ( x ) = e x f(x) = e^x f ( x ) = e x d d x [ e x ] = e x \frac{d}{dx} [e^x] = e^x d x d [ e x ] = e x f ( x ) = 2 e 2 x f(x) = 2e^{2x} f ( x ) = 2 e 2 x d d x [ 2 e 2 x ] = 4 e 2 x \frac{d}{dx} [2e^{2x}] = 4e^{2x} d x d [ 2 e 2 x ] = 4 e 2 x 对数函数 :
f ( x ) = ln ( x ) f(x) = \ln(x) f ( x ) = ln ( x ) d d x [ ln ( x ) ] = 1 x \frac{d}{dx} [\ln(x)] = \frac{1}{x} d x d [ ln ( x )] = x 1 f ( x ) = 3 ln ( 2 x ) f(x) = 3\ln(2x) f ( x ) = 3 ln ( 2 x ) d d x [ 3 ln ( 2 x ) ] = 3 x \frac{d}{dx} [3\ln(2x)] = \frac{3}{x} d x d [ 3 ln ( 2 x )] = x 3 三角函数 :
f ( x ) = sin ( x ) f(x) = \sin(x) f ( x ) = sin ( x ) d d x [ sin ( x ) ] = cos ( x ) \frac{d}{dx} [\sin(x)] = \cos(x) d x d [ sin ( x )] = cos ( x ) f ( x ) = 2 cos ( 3 x ) f(x) = 2\cos(3x) f ( x ) = 2 cos ( 3 x ) d d x [ 2 cos ( 3 x ) ] = − 6 sin ( 3 x ) \frac{d}{dx} [2\cos(3x)] = -6\sin(3x) d x d [ 2 cos ( 3 x )] = − 6 sin ( 3 x ) 幂函数 :
f ( x ) = x 0.5 f(x) = x^{0.5} f ( x ) = x 0.5 d d x [ x 0.5 ] = 1 2 x \frac{d}{dx} [x^{0.5}] = \frac{1}{2\sqrt{x}} d x d [ x 0.5 ] = 2 x 1 f ( x ) = 3 x − 2 f(x) = 3x^{-2} f ( x ) = 3 x − 2 d d x [ 3 x − 2 ] = − 6 x − 3 \frac{d}{dx} [3x^{-2}] = -6x^{-3} d x d [ 3 x − 2 ] = − 6 x − 3 这里给出的是一阶导数的示例。
可微是什么意思? "可微"是微积分中的一个重要概念,指的是函数在某一点上具有导数,也就是函数在该点附近能够通过一条切线来近似描述。
一个函数 f ( x ) f(x) f ( x ) x 0 x_0 x 0 a a a x x x x 0 x_0 x 0 f ( x ) f(x) f ( x )
f ( x ) ≈ f ( x 0 ) + a ( x − x 0 ) . f(x) \approx f(x_0) + a(x - x_0). f ( x ) ≈ f ( x 0 ) + a ( x − x 0 ) .
其中,f ( x 0 ) f(x_0) f ( x 0 ) x 0 x_0 x 0 x − x 0 x - x_0 x − x 0 x x x x 0 x_0 x 0 a a a
换句话说,一个可微函数在某一点附近的行为可以用一条切线来近似描述。这个概念在微积分中非常重要,因为它涉及到函数的变化率以及函数在特定点的局部性质。函数在每一个可微点都有一个对应的导数,可以用来描述函数在该点的斜率和变化速率。
有一些函数在某些点上不可微,这些点通常包括以下情况:
不连续点 :在不连续点,函数的导数通常不存在。例如,绝对值函数 ∣ x ∣ |x| ∣ x ∣ x = 0 x = 0 x = 0
角点和尖点 :函数在角点(如绝对值函数的尖点)或者尖点(如锐角转折点)处也可能不可微。这是因为在这些点上函数的变化过于剧烈,没有一个单一的切线能够合理地近似函数的行为。
间断点 :函数在某些间断点上可能不可微。一个间断点是一个点,函数在该点的左右极限不相等。在间断点上,函数的变化也可能太大以至于没有明确的切线。
奇点 :在奇点,函数的导数可能不存在或趋近于无穷大。例如,函数 f ( x ) = 1 x f(x) = \frac{1}{x} f ( x ) = x 1 x = 0 x = 0 x = 0
多项式函数的某些阶数上 :尽管多项式函数一般来说是可微的,但在某些阶数上它们可能不可微。例如,整数次幂小于零的阶数,如 x − 1 x^{-1} x − 1 x = 0 x = 0 x = 0
总之,不可微函数通常与函数在某些点的特定行为相关,其中函数的变化过于剧烈、不连续或者在某些方面没有平滑的特性。在这些点上,导数无法通过单一的切线来描述函数的变化率。
微分和导数的关系是什么? 微分和导数是紧密相关的概念,它们在微积分中都涉及函数的变化率,但从不同的角度来看待。
导数是微分的特殊情况,可以将导数看作是微分在某一点的具体值。更具体地说,函数 f ( x ) f(x) f ( x ) x 0 x_0 x 0 f ′ ( x 0 ) f'(x_0) f ′ ( x 0 ) x 0 x_0 x 0
换句话说,导数是函数变化率的函数,它告诉我们在整个定义域上的每一点处函数的变化率。而微分是指函数在特定点处的变化率,它可以看作是导数在某一点的极限情况。因此,导数和微分之间的关系可以总结如下:
导数是函数在每一点处的微分值。 微分是导数在某一点的极限情况,即微小变化趋近于零时的导数值。 这两个概念密切相关,共同构成了微积分的基础。通过理解导数和微分的关系,我们可以更好地理解函数的变化以及曲线的性质。
微分和导数的示意图:
import torch def f ( x ) : return x ** 2 x0 = torch . tensor ( 3.0 , requires_grad = True ) y = f ( x0 ) y . backward ( ) derivative = x0 . grad . item ( ) differential = f ( x0 ) . item ( ) print ( "Function value at x =" , x0 . item ( ) , ":" , differential ) print ( "Derivative at x =" , x0 . item ( ) , ":" , derivative ) Function value at x = 3.0 : 9.0 Derivative at x = 3.0 : 6.0 导数的几个等价符号 当处理函数的导数时,常常需要运用以下法则来进行计算。这些法则可以用数学符号表示如下:
常数相乘法则 :
如果 f ( x ) f(x) f ( x ) c c c d d x [ c ⋅ f ( x ) ] \frac{d}{dx} [c \cdot f(x)] d x d [ c ⋅ f ( x )] c ⋅ d d x [ f ( x ) ] c \cdot \frac{d}{dx} [f(x)] c ⋅ d x d [ f ( x )]
例子 :
设 f ( x ) = 3 x 2 f(x) = 3x^2 f ( x ) = 3 x 2 c = 2 c = 2 c = 2
d d x [ 2 ⋅ 3 x 2 ] = 2 ⋅ d d x [ 3 x 2 ] = 2 ⋅ 6 x = 12 x . \frac{d}{dx} [2 \cdot 3x^2] = 2 \cdot \frac{d}{dx} [3x^2] = 2 \cdot 6x = 12x. d x d [ 2 ⋅ 3 x 2 ] = 2 ⋅ d x d [ 3 x 2 ] = 2 ⋅ 6 x = 12 x . 加法法则 :
如果 f ( x ) f(x) f ( x ) g ( x ) g(x) g ( x ) d d x [ f ( x ) + g ( x ) ] \frac{d}{dx} [f(x) + g(x)] d x d [ f ( x ) + g ( x )] d d x [ f ( x ) ] + d d x [ g ( x ) ] \frac{d}{dx} [f(x)] + \frac{d}{dx} [g(x)] d x d [ f ( x )] + d x d [ g ( x )]
例子 :
设 f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2 g ( x ) = 3 x g(x) = 3x g ( x ) = 3 x
d d x [ x 2 + 3 x ] = d d x [ x 2 ] + d d x [ 3 x ] = 2 x + 3. \frac{d}{dx} [x^2 + 3x] = \frac{d}{dx} [x^2] + \frac{d}{dx} [3x] = 2x + 3. d x d [ x 2 + 3 x ] = d x d [ x 2 ] + d x d [ 3 x ] = 2 x + 3. 乘法法则 :
如果 f ( x ) f(x) f ( x ) g ( x ) g(x) g ( x ) d d x [ f ( x ) ⋅ g ( x ) ] \frac{d}{dx} [f(x) \cdot g(x)] d x d [ f ( x ) ⋅ g ( x )] f ( x ) ⋅ d d x [ g ( x ) ] + g ( x ) ⋅ d d x [ f ( x ) ] f(x) \cdot \frac{d}{dx} [g(x)] + g(x) \cdot \frac{d}{dx} [f(x)] f ( x ) ⋅ d x d [ g ( x )] + g ( x ) ⋅ d x d [ f ( x )]
例子 :
设 f ( x ) = x f(x) = x f ( x ) = x g ( x ) = x 2 g(x) = x^2 g ( x ) = x 2
d d x [ x ⋅ x 2 ] = x ⋅ d d x [ x 2 ] + x 2 ⋅ d d x [ x ] = x ⋅ 2 x + x 2 ⋅ 1 = 3 x 2 . \frac{d}{dx} [x \cdot x^2] = x \cdot \frac{d}{dx} [x^2] + x^2 \cdot \frac{d}{dx} [x] = x \cdot 2x + x^2 \cdot 1 = 3x^2. d x d [ x ⋅ x 2 ] = x ⋅ d x d [ x 2 ] + x 2 ⋅ d x d [ x ] = x ⋅ 2 x + x 2 ⋅ 1 = 3 x 2 . 除法法则 :
如果 f ( x ) f(x) f ( x ) g ( x ) g(x) g ( x ) g ( x ) g(x) g ( x ) d d x [ f ( x ) g ( x ) ] \frac{d}{dx} \left[\frac{f(x)}{g(x)}\right] d x d [ g ( x ) f ( x ) ] g ( x ) ⋅ d d x [ f ( x ) ] − f ( x ) ⋅ d d x [ g ( x ) ] ( g ( x ) ) 2 \frac{g(x) \cdot \frac{d}{dx}[f(x)] - f(x) \cdot \frac{d}{dx}[g(x)]}{(g(x))^2} ( g ( x ) ) 2 g ( x ) ⋅ d x d [ f ( x )] − f ( x ) ⋅ d x d [ g ( x )]
例子 :
设 f ( x ) = 1 f(x) = 1 f ( x ) = 1 g ( x ) = x g(x) = x g ( x ) = x
d d x [ 1 x ] = x ⋅ d d x [ 1 ] − 1 ⋅ d d x [ x ] x 2 = 0 − 1 x 2 = − 1 x 2 . \frac{d}{dx} \left[\frac{1}{x}\right] = \frac{x \cdot \frac{d}{dx}[1] - 1 \cdot \frac{d}{dx}[x]}{x^2} = \frac{0 - 1}{x^2} = -\frac{1}{x^2}. d x d [ x 1 ] = x 2 x ⋅ d x d [ 1 ] − 1 ⋅ d x d [ x ] = x 2 0 − 1 = − x 2 1 . 这些法则是求导过程中常用的工具,可以帮助简化函数的导数计算。
偏导数 偏导数是多元函数的导数概念的推广,用于描述函数在多个变量中的变化率。当一个函数依赖于多个变量时,每个变量的变化都可能影响函数的值。偏导数衡量了在其他变量保持不变的情况下,函数相对于某个特定变量的变化率。
形式上,如果有一个函数 f ( x 1 , x 2 , … , x n ) f(x_1, x_2, \ldots, x_n) f ( x 1 , x 2 , … , x n ) i i i x i x_i x i ∂ f ∂ x i \frac{\partial f}{\partial x_i} ∂ x i ∂ f f f f x i x_i x i
以下是一些例子来说明偏导数的概念:
二元函数的偏导数 :
考虑函数 f ( x , y ) = x 2 + 2 x y + y 2 f(x, y) = x^2 + 2xy + y^2 f ( x , y ) = x 2 + 2 x y + y 2 x x x y y y ∂ f ∂ x = 2 x + 2 y \frac{\partial f}{\partial x} = 2x + 2y ∂ x ∂ f = 2 x + 2 y y y y x x x ∂ f ∂ y = 2 x + 2 y \frac{\partial f}{\partial y} = 2x + 2y ∂ y ∂ f = 2 x + 2 y x x x y y y
三元函数的偏导数 :
考虑函数 g ( x , y , z ) = x 2 + y 2 + z 2 g(x, y, z) = x^2 + y^2 + z^2 g ( x , y , z ) = x 2 + y 2 + z 2 x x x y y y z z z ∂ g ∂ x = 2 x \frac{\partial g}{\partial x} = 2x ∂ x ∂ g = 2 x y y y z z z x x x ∂ g ∂ y = 2 y \frac{\partial g}{\partial y} = 2y ∂ y ∂ g = 2 y x x x z z z y y y ∂ g ∂ z = 2 z \frac{\partial g}{\partial z} = 2z ∂ z ∂ g = 2 z x x x y y y z z z
当涉及到计算偏导数时,以下是一些常见的例子,展示了如何根据不同的函数类型计算偏导数:
一元多次函数 :考虑函数 f ( x ) = x 3 + 2 x 2 − 5 x + 7 f(x) = x^3 + 2x^2 - 5x + 7 f ( x ) = x 3 + 2 x 2 − 5 x + 7 x x x
d f d x = 3 x 2 + 4 x − 5 \frac{df}{dx} = 3x^2 + 4x - 5 d x df = 3 x 2 + 4 x − 5 多元函数 :考虑函数 g ( x , y ) = x 2 + 3 x y + y 2 g(x, y) = x^2 + 3xy + y^2 g ( x , y ) = x 2 + 3 x y + y 2 x x x y y y
∂ g ∂ x = 2 x + 3 y \frac{\partial g}{\partial x} = 2x + 3y ∂ x ∂ g = 2 x + 3 y ∂ g ∂ y = 3 x + 2 y \frac{\partial g}{\partial y} = 3x + 2y ∂ y ∂ g = 3 x + 2 y 指数函数 :考虑函数 h ( x ) = e 2 x h(x) = e^{2x} h ( x ) = e 2 x x x x
d h d x = 2 e 2 x \frac{dh}{dx} = 2e^{2x} d x d h = 2 e 2 x 三角函数 :考虑函数 k ( x ) = sin ( 3 x ) k(x) = \sin(3x) k ( x ) = sin ( 3 x ) x x x
d k d x = 3 cos ( 3 x ) \frac{dk}{dx} = 3\cos(3x) d x d k = 3 cos ( 3 x ) 复合函数 :考虑函数 p ( u , v ) = u 3 + v 2 p(u, v) = u^3 + v^2 p ( u , v ) = u 3 + v 2 u = 2 x + 1 u = 2x + 1 u = 2 x + 1 v = 3 y − 2 v = 3y - 2 v = 3 y − 2 x x x y y y
使用链式法则,∂ p ∂ x = ∂ p ∂ u ⋅ ∂ u ∂ x = 3 u 2 ⋅ 2 = 6 ( 2 x + 1 ) 2 \frac{\partial p}{\partial x} = \frac{\partial p}{\partial u} \cdot \frac{\partial u}{\partial x} = 3u^2 \cdot 2 = 6(2x + 1)^2 ∂ x ∂ p = ∂ u ∂ p ⋅ ∂ x ∂ u = 3 u 2 ⋅ 2 = 6 ( 2 x + 1 ) 2 同理,∂ p ∂ y = ∂ p ∂ v ⋅ ∂ v ∂ y = 2 v ⋅ 3 = 6 ( 3 y − 2 ) \frac{\partial p}{\partial y} = \frac{\partial p}{\partial v} \cdot \frac{\partial v}{\partial y} = 2v \cdot 3 = 6(3y - 2) ∂ y ∂ p = ∂ v ∂ p ⋅ ∂ y ∂ v = 2 v ⋅ 3 = 6 ( 3 y − 2 ) 向量范数的平方 :考虑函数 q ( x ) = ∥ x ∥ 2 q(\mathbf{x}) = \|\mathbf{x}\|^2 q ( x ) = ∥ x ∥ 2 x = [ x 1 , x 2 , … , x n ] \mathbf{x} = [x_1, x_2, \ldots, x_n] x = [ x 1 , x 2 , … , x n ] x \mathbf{x} x
使用向量的分量表示,∂ q ∂ x i = 2 x i \frac{\partial q}{\partial x_i} = 2x_i ∂ x i ∂ q = 2 x i ∇ x q = 2 x \nabla_{\mathbf{x}} q = 2\mathbf{x} ∇ x q = 2 x 这些例子涵盖了不同类型的函数和计算方法,从一元函数到多元函数、复合函数和特殊函数。对于更复杂的函数,可能需要应用多个规则(如链式法则、乘积法则等)以及代数运算来计算偏导数。
当计算函数的偏导数时,逐步进行推导可以帮助理解每一步的计算过程。以下是两个例子,分别介绍计算关于 x x x
例子 1:多元函数的偏导数计算
考虑函数 f ( x , y ) = x 2 + 3 x y + y 2 f(x, y) = x^2 + 3xy + y^2 f ( x , y ) = x 2 + 3 x y + y 2 x x x ∂ f ∂ x \frac{\partial f}{\partial x} ∂ x ∂ f y y y ∂ f ∂ y \frac{\partial f}{\partial y} ∂ y ∂ f
计算 ∂ f ∂ x \frac{\partial f}{\partial x} ∂ x ∂ f
将 f ( x , y ) f(x, y) f ( x , y ) x x x 对于每一项 x 2 x^2 x 2 3 x y 3xy 3 x y y 2 y^2 y 2 x x x ∂ ∂ x ( x 2 ) = 2 x \frac{\partial}{\partial x}(x^2) = 2x ∂ x ∂ ( x 2 ) = 2 x ∂ ∂ x ( 3 x y ) = 3 y \frac{\partial}{\partial x}(3xy) = 3y ∂ x ∂ ( 3 x y ) = 3 y ∂ ∂ x ( y 2 ) = 0 \frac{\partial}{\partial x}(y^2) = 0 ∂ x ∂ ( y 2 ) = 0 y y y 把这些导数相加,得到 ∂ f ∂ x = 2 x + 3 y \frac{\partial f}{\partial x} = 2x + 3y ∂ x ∂ f = 2 x + 3 y 计算 ∂ f ∂ y \frac{\partial f}{\partial y} ∂ y ∂ f
类似地,将 f ( x , y ) f(x, y) f ( x , y ) y y y 对于每一项 x 2 x^2 x 2 3 x y 3xy 3 x y y 2 y^2 y 2 y y y ∂ ∂ y ( x 2 ) = 0 \frac{\partial}{\partial y}(x^2) = 0 ∂ y ∂ ( x 2 ) = 0 x x x ∂ ∂ y ( 3 x y ) = 3 x \frac{\partial}{\partial y}(3xy) = 3x ∂ y ∂ ( 3 x y ) = 3 x ∂ ∂ y ( y 2 ) = 2 y \frac{\partial}{\partial y}(y^2) = 2y ∂ y ∂ ( y 2 ) = 2 y 把这些导数相加,得到 ∂ f ∂ y = 3 x + 2 y \frac{\partial f}{\partial y} = 3x + 2y ∂ y ∂ f = 3 x + 2 y 例子 2:复合函数的偏导数计算
考虑函数 g ( x ) = e 2 x 2 g(x) = e^{2x^2} g ( x ) = e 2 x 2 x x x d g d x \frac{dg}{dx} d x d g
将 g ( x ) g(x) g ( x ) u = 2 x 2 u = 2x^2 u = 2 x 2 计算 u u u x x x d u d x \frac{du}{dx} d x d u 使用链式法则,d u d x = d d x ( 2 x 2 ) = 4 x \frac{du}{dx} = \frac{d}{dx}(2x^2) = 4x d x d u = d x d ( 2 x 2 ) = 4 x 计算 g ( u ) g(u) g ( u ) u u u d g d u \frac{dg}{du} d u d g g ( u ) = e u g(u) = e^u g ( u ) = e u d g d u = e u \frac{dg}{du} = e^u d u d g = e u 使用链式法则,计算 d g d x \frac{dg}{dx} d x d g d g d x = d g d u ⋅ d u d x = e 2 x 2 ⋅ 4 x = 4 x e 2 x 2 \frac{dg}{dx} = \frac{dg}{du} \cdot \frac{du}{dx} = e^{2x^2} \cdot 4x = 4xe^{2x^2} d x d g = d u d g ⋅ d x d u = e 2 x 2 ⋅ 4 x = 4 x e 2 x 2 在这两个例子中,我们分别计算了关于 x x x
梯度是什么? 梯度是一个向量,它在多元函数中表示函数变化最快的方向和速率。对于一个具有多个变量的函数,梯度指向函数在某一点上变化最快的方向,并且梯度的长度表示了这个变化的速率 。梯度在微积分、优化问题和机器学习中都有重要应用。
对于一个具有多个变量的函数,梯度指向函数在某一点上变化最快的方向,并且梯度的长度表示了这个变化的速率。梯度在微积分、优化问题和机器学习中都有重要应用。
你可以想象在群山之中,某个山的半山腰有只小兔子打算使用梯度下降的思路去往这片群山最深的山谷里找水喝。
我们用变化率来描述下山时各个方向的山路有多陡峭,往下的的路越陡峭变化率越大。山路险远,小兔子下山的过程中每个方向山路的陡峭程度都不一样:
东边是万丈深渊,往东边的变化率就一百颗星; 南边是下缓坡,往南方向的变化率小一些,三颗星; 西边是另一座山头要往上爬的,那么往西的变化率是负的十颗星; 北边是一个平地,变化率几乎为零,一颗星。 虽然东南西北各个方向都有变化率,但梯度下降的思想就是通过梯度最快的收敛,而梯度就是这几个方向中变化率最大的方向和值(为什么最大后面会说明),注意梯度同时描述了两个值,方向和大小,是个向量。放在这里,梯度就是东边和一百颗星。
然后梯度下降的思想就指导着我们的小兔子向东走,于是它轻轻一跃,移动了大约一万丈,没什么比直接跳下去更快能喝到水的了
梯度下降过程就是小兔子找水喝的过程。
机器学习领域,我们有一个步长(记为 γ \gamma γ ∇ \nabla ∇
上边的说明可以用来感性的感受一下梯度是啥,和梯度下降是想要干嘛。
形式上,考虑一个多元函数 f ( x 1 , x 2 , … , x n ) f(x_1, x_2, \ldots, x_n) f ( x 1 , x 2 , … , x n ) ∇ f \nabla f ∇ f ∇ ⃗ f \vec{\nabla} f ∇ f
∇ f = ∂ f ∂ x 1 i ⃗ + ∂ f ∂ x 2 j ⃗ + … + ∂ f ∂ x n k ⃗ , \nabla f = \frac{\partial f}{\partial x_1} \vec{i} + \frac{\partial f}{\partial x_2} \vec{j} + \ldots + \frac{\partial f}{\partial x_n} \vec{k}, ∇ f = ∂ x 1 ∂ f i + ∂ x 2 ∂ f j + … + ∂ x n ∂ f k , 其中 i ⃗ \vec{i} i j ⃗ \vec{j} j k ⃗ \vec{k} k
梯度的各个分量是函数在每个相应变量方向上的偏导数。因此,梯度的方向是变化最快的方向,而梯度的大小表示了在该方向上的变化率。
举个例子,考虑函数 f ( x , y ) = x 2 + 2 y 2 f(x, y) = x^2 + 2y^2 f ( x , y ) = x 2 + 2 y 2
∇ f = ∂ f ∂ x i ⃗ + ∂ f ∂ y j ⃗ = 2 x i ⃗ + 4 y j ⃗ . \nabla f = \frac{\partial f}{\partial x} \vec{i} + \frac{\partial f}{\partial y} \vec{j} = 2x \vec{i} + 4y \vec{j}. ∇ f = ∂ x ∂ f i + ∂ y ∂ f j = 2 x i + 4 y j . 在点 ( 1 , 2 ) (1, 2) ( 1 , 2 ) 2 i ⃗ + 8 j ⃗ 2\vec{i} + 8\vec{j} 2 i + 8 j 2 i ⃗ + 8 j ⃗ 2\vec{i} + 8\vec{j} 2 i + 8 j
举个简单的例子,考虑一个二维平面上的函数 f ( x , y ) = x 2 + y 2 f(x, y) = x^2 + y^2 f ( x , y ) = x 2 + y 2
在这个例子中,我们可以计算函数 f ( x , y ) f(x, y) f ( x , y ) ( 1 , 1 ) (1, 1) ( 1 , 1 )
∇ f ( 1 , 1 ) = ∂ f ∂ x ( 1 , 1 ) i ⃗ + ∂ f ∂ y ( 1 , 1 ) j ⃗ = 2 i ⃗ + 2 j ⃗ . \nabla f(1, 1) = \frac{\partial f}{\partial x}(1, 1) \vec{i} + \frac{\partial f}{\partial y}(1, 1) \vec{j} = 2 \vec{i} + 2 \vec{j}. ∇ f ( 1 , 1 ) = ∂ x ∂ f ( 1 , 1 ) i + ∂ y ∂ f ( 1 , 1 ) j = 2 i + 2 j . 这意味着在点 ( 1 , 1 ) (1, 1) ( 1 , 1 ) 2 i ⃗ + 2 j ⃗ 2 \vec{i} + 2 \vec{j} 2 i + 2 j
以图形来看,你可以想象站在函数图像上的点 ( 1 , 1 ) (1, 1) ( 1 , 1 ) 2 i ⃗ + 2 j ⃗ 2 \vec{i} + 2 \vec{j} 2 i + 2 j ( 1 , 1 ) (1, 1) ( 1 , 1 )
假设 x 为 n 维向量,在微分多元函数时经常使用以下规则:
对于所有 A ∈ R m × x A \in \mathbb{R}^{m \times x} A ∈ R m × x ∇ x ( A x ) = A T \nabla_x (Ax) = A^T ∇ x ( A x ) = A T 对于所有 A ∈ R x × m A \in \mathbb{R}^{x \times m} A ∈ R x × m ∇ x ( x T A ) = A \nabla_x (x^TA) = A ∇ x ( x T A ) = A 对于所有 A ∈ R n × n A \in \mathbb{R}^{n \times n} A ∈ R n × n ∇ x ( x T A x ) = ( A + A T ) x \nabla_x (x^TAx) = (A + A^T)x ∇ x ( x T A x ) = ( A + A T ) x 对于所有 ∇ x ( x T x ) = ∇ x ∥ x ∥ 2 = 2 x \nabla_x (x^Tx) = \nabla_x \|x\|^2 = 2x ∇ x ( x T x ) = ∇ x ∥ x ∥ 2 = 2 x 这些表达式涉及矩阵和向量的微分。逐个解释每个表达式的含义:
∇ x ( A x ) = A T \nabla_x (Ax) = A^T ∇ x ( A x ) = A T
这个表达式表示对于一个矩阵 A A A x x x A A A A T A^T A T 这个规则反映了矩阵乘法的导数性质。 ∇ x ( x T A ) = A \nabla_x (x^TA) = A ∇ x ( x T A ) = A
这个表达式表示对于一个矩阵 A A A x x x A A A 这个规则是矩阵向量乘法的导数性质。 ∇ x ( x T A x ) = ( A + A T ) x \nabla_x (x^TAx) = (A + A^T)x ∇ x ( x T A x ) = ( A + A T ) x
这个表达式表示对于一个矩阵 A A A x x x x T A x x^TAx x T A x ( A + A T ) x (A + A^T)x ( A + A T ) x 这个规则展示了二次型函数关于向量的梯度计算,其中 A T A^T A T A A A ∇ x ( x T x ) = ∇ x ∥ x ∥ 2 = 2 x \nabla_x (x^Tx) = \nabla_x \|x\|^2 = 2x ∇ x ( x T x ) = ∇ x ∥ x ∥ 2 = 2 x
这个表达式表示对于向量 x x x x T x x^Tx x T x ∥ x ∥ 2 \|x\|^2 ∥ x ∥ 2 x x x 2 x 2x 2 x 这个规则说明了向量的内积和范数平方的梯度计算。 总之,这些表达式是微积分中关于矩阵和向量的微分规则的具体应用。它们有助于在多变量计算中求解复杂函数的导数。
范数平方是指向量的范数(或长度)的平方。在数学和线性代数中,向量的范数是一个表示向量大小的概念。对于 n n n x = [ x 1 , x 2 , … , x n ] x = [x_1, x_2, \ldots, x_n] x = [ x 1 , x 2 , … , x n ] ∥ x ∥ \|x\| ∥ x ∥
∥ x ∥ = x 1 2 + x 2 2 + … + x n 2 . \|x\| = \sqrt{x_1^2 + x_2^2 + \ldots + x_n^2}. ∥ x ∥ = x 1 2 + x 2 2 + … + x n 2 .
而范数平方则是将范数的平方,即各个分量平方和的平方根,取平方,即:
∥ x ∥ 2 = x 1 2 + x 2 2 + … + x n 2 . \|x\|^2 = x_1^2 + x_2^2 + \ldots + x_n^2. ∥ x ∥ 2 = x 1 2 + x 2 2 + … + x n 2 .
范数平方的概念在某些情况下更加方便,因为它避免了开平方运算,可能在某些计算中减少复杂性。范数平方的概念用于计算向量函数的导数,这是因为其在计算上更加方便。
这些规则是微分多元函数时经常使用的基本规则。通过这些规则,你可以计算复杂的多元函数的偏导数。需要注意的是,当涉及到更高阶的偏导数、偏导数的交换次序等情况时,可能会涉及到更多的规则和性质。
总之,梯度是函数变化最快的方向和速率的表示,它在多个领域中都有着重要的应用。
梯度和导数有什么区别? 梯度(Gradient)和导数(Derivative)都涉及到函数的变化率,但它们在数学上和应用上有一些区别。以下是它们的区别:
导数:
导数是一个函数关于其自变量的变化率。对于一个一元函数 f ( x ) f(x) f ( x ) 导数通常用于描述函数在一个点上的切线斜率。如果函数是一元函数,导数是一个标量;如果函数是多元函数,导数是一个梯度向量。 导数可以理解为函数在无穷小变化下的响应。 对于一元函数 f ( x ) f(x) f ( x ) f ′ ( x ) f'(x) f ′ ( x ) d f d x \frac{df}{dx} d x df 在多元函数的情况下,导数可以视为梯度向量。对于一个多元函数 f ( x ) f(\mathbf{x}) f ( x ) x \mathbf{x} x
当在多元函数的上下文中谈论导数时,通常会使用术语“梯度”,尤其是当涉及优化问题和机器学习时。在这些情况下,梯度向量告诉我们在哪个方向上函数变化最快,可以用于指导参数的更新,以便在优化过程中找到函数的极值。
因此,在张量计算中,"梯度" 通常指的是偏导数的概念 ,尤其是在深度学习中的优化问题中。当你计算一个张量相对于其他张量或变量的偏导数时,结果被称为梯度。这种偏导数的计算是通过自动微分(Automatic Differentiation)系统来实现的。
在机器学习中,我们经常要优化一个损失函数,使其最小化或最大化。这涉及到计算损失函数相对于模型参数(通常是权重和偏置)的梯度,以便用梯度下降等优化算法更新参数。在这个上下文中,梯度实际上就是对应于损失函数的偏导数,用来指导参数的更新方向。
总之,在张量计算和机器学习中,"梯度" 通常用来表示偏导数,它对于优化问题和模型训练非常关键。
梯度:
梯度是多元函数的变化率。对于一个多元函数 f ( x ) f(\mathbf{x}) f ( x ) 梯度包含了所有偏导数,每个分量表示了函数相对于一个自变量的变化率。 梯度可以理解为函数在某点上的变化率,相对于所有输入变量的综合影响。 对于多元函数 f ( x ) f(\mathbf{x}) f ( x ) ∇ f ( x ) \nabla f(\mathbf{x}) ∇ f ( x ) ∇ \nabla ∇ 总结:
导数用于描述函数关于一个变量的变化率,通常是一个标量值。 梯度用于描述函数关于多个变量的变化率,是一个包含多个偏导数的向量。 尽管两者的数学定义不同,但在很多情况下,梯度和导数都可以在某种程度上指向函数的变化率。在优化问题和机器学习中,梯度是一个重要的概念,用于指导参数更新,以便优化模型。
回顾:范数是什么? 在线性代数中,范数是用来衡量向量大小(长度)的一种数学概念。范数通常满足一些基本性质,例如非负性、齐次性和三角不等式。不同的范数有不同的定义方式,但它们都旨在提供一个量化向量大小的方法。
对于一个 n n n x = [ x 1 , x 2 , … , x n ] \mathbf{x} = [x_1, x_2, \ldots, x_n] x = [ x 1 , x 2 , … , x n ] ∥ x ∥ \|\mathbf{x}\| ∥ x ∥
∥ x ∥ = x 1 2 + x 2 2 + … + x n 2 . \|\mathbf{x}\| = \sqrt{x_1^2 + x_2^2 + \ldots + x_n^2}. ∥ x ∥ = x 1 2 + x 2 2 + … + x n 2 .
这被称为欧几里德范数或者 L 2 L^2 L 2
L 1 L^1 L 1 ∥ x ∥ 1 = ∣ x 1 ∣ + ∣ x 2 ∣ + … + ∣ x n ∣ \|\mathbf{x}\|_1 = |x_1| + |x_2| + \ldots + |x_n| ∥ x ∥ 1 = ∣ x 1 ∣ + ∣ x 2 ∣ + … + ∣ x n ∣
L ∞ L^\infty L ∞ ∥ x ∥ ∞ = max ( ∣ x 1 ∣ , ∣ x 2 ∣ , … , ∣ x n ∣ ) \|\mathbf{x}\|_\infty = \max(|x_1|, |x_2|, \ldots, |x_n|) ∥ x ∥ ∞ = max ( ∣ x 1 ∣ , ∣ x 2 ∣ , … , ∣ x n ∣ )
这些范数具有不同的性质和应用,它们在数学、工程、物理等领域中都有广泛的用途。范数可以用来度量向量之间的距离、定义优化问题的约束、表示向量的稀疏性等。
链式法则 链式法则是微积分中一个重要的规则,用于计算复合函数的导数。复合函数是由一个函数嵌套在另一个函数内部形成的,链式法则允许我们找到这样的复合函数的导数。
设有两个函数 f ( u ) f(u) f ( u ) u ( x ) u(x) u ( x ) y ( x ) = f ( u ( x ) ) y(x) = f(u(x)) y ( x ) = f ( u ( x ))
d y d x = d y d u ⋅ d u d x . \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx}. d x d y = d u d y ⋅ d x d u .
其中:
d y d x \frac{dy}{dx} d x d y y ( x ) y(x) y ( x ) x x x d y d u \frac{dy}{du} d u d y f ( u ) f(u) f ( u ) u u u d u d x \frac{du}{dx} d x d u u ( x ) u(x) u ( x ) x x x 链式法则的直观解释是,当我们微小地改变自变量 x x x u u u f f f d u du d u d y dy d y y ( x ) y(x) y ( x ) d y dy d y
在多元函数的情况下,链式法则也可以推广。假设有函数 f ( u 1 , u 2 , … , u n ) f(u_1, u_2, \ldots, u_n) f ( u 1 , u 2 , … , u n ) u ( x 1 , x 2 , … , x m ) = [ u 1 ( x 1 , x 2 , … , x m ) , u 2 ( x 1 , x 2 , … , x m ) , … , u n ( x 1 , x 2 , … , x m ) ] \mathbf{u}(x_1, x_2, \ldots, x_m) = [u_1(x_1, x_2, \ldots, x_m), u_2(x_1, x_2, \ldots, x_m), \ldots, u_n(x_1, x_2, \ldots, x_m)] u ( x 1 , x 2 , … , x m ) = [ u 1 ( x 1 , x 2 , … , x m ) , u 2 ( x 1 , x 2 , … , x m ) , … , u n ( x 1 , x 2 , … , x m )] y ( x ) = f ( u ( x ) ) \mathbf{y}(\mathbf{x}) = f(\mathbf{u}(\mathbf{x})) y ( x ) = f ( u ( x ))
链式法则在各种领域都有广泛的应用,包括物理、工程、经济学等,特别是在描述多个变量之间的复杂相互关系时。
实例:向量求导 如何对 y = 2 x T x y = 2x^Tx y = 2 x T x
首先,让我们明确一下符号的含义:x x x x T x^T x T x x x 2 x T 2x^T 2 x T
函数 y = 2 x T x y = 2x^Tx y = 2 x T x x x x x x x
矩阵微分法则在这里可以看作链式法则的推广。
首先,计算 y y y x x x n n n x x x
y = 2 x T x = 2 ( x 1 2 + x 2 2 + … + x n 2 ) . y = 2x^Tx = 2(x_1^2 + x_2^2 + \ldots + x_n^2). y = 2 x T x = 2 ( x 1 2 + x 2 2 + … + x n 2 ) .
现在对 y y y x x x i i i ∂ y ∂ x i \frac{\partial y}{\partial x_i} ∂ x i ∂ y
∂ y ∂ x i = ∂ y ∂ ( x 1 2 + x 2 2 + … + x n 2 ) ⋅ ∂ ( x 1 2 + x 2 2 + … + x n 2 ) ∂ x i . \frac{\partial y}{\partial x_i} = \frac{\partial y}{\partial (x_1^2 + x_2^2 + \ldots + x_n^2)} \cdot \frac{\partial (x_1^2 + x_2^2 + \ldots + x_n^2)}{\partial x_i}. ∂ x i ∂ y = ∂ ( x 1 2 + x 2 2 + … + x n 2 ) ∂ y ⋅ ∂ x i ∂ ( x 1 2 + x 2 2 + … + x n 2 ) .
第一个偏导数是常数倍数,即 ∂ y ∂ ( x 1 2 + x 2 2 + … + x n 2 ) = 2 \frac{\partial y}{\partial (x_1^2 + x_2^2 + \ldots + x_n^2)} = 2 ∂ ( x 1 2 + x 2 2 + … + x n 2 ) ∂ y = 2
第二个偏导数是分量 x i x_i x i ∂ ( x 1 2 + x 2 2 + … + x n 2 ) ∂ x i = 2 x i \frac{\partial (x_1^2 + x_2^2 + \ldots + x_n^2)}{\partial x_i} = 2x_i ∂ x i ∂ ( x 1 2 + x 2 2 + … + x n 2 ) = 2 x i
将这两个部分相乘,得到 ∂ y ∂ x i = 2 ⋅ 2 x i = 4 x i \frac{\partial y}{\partial x_i} = 2 \cdot 2x_i = 4x_i ∂ x i ∂ y = 2 ⋅ 2 x i = 4 x i
所以,对于列向量 x x x 4 x i 4x_i 4 x i x x x
∇ x ( 2 x T x ) = [ 4 x 1 , 4 x 2 , … , 4 x n ] . \nabla_x (2x^Tx) = [4x_1, 4x_2, \ldots, 4x_n]. ∇ x ( 2 x T x ) = [ 4 x 1 , 4 x 2 , … , 4 x n ] .
也可以写成更紧凑的形式:
∇ x ( 2 x T x ) = 4 x . \nabla_x (2x^Tx) = 4x. ∇ x ( 2 x T x ) = 4 x .
使用 PyTorch 自动求导 在 PyTorch 中,grad 是一个属性,用于跟踪张量(Tensor)的梯度(导数)。梯度表示了一个函数关于变量的变化率,对于深度学习中的优化问题,梯度可以告诉我们如何调整变量以最小化或最大化目标函数。PyTorch 使用自动微分(Automatic Differentiation)技术来计算张量的梯度,并将这些梯度存储在 grad 属性中。
在 PyTorch 中,要使用自动微分,需要将张量设置为可求导的(requires_grad=True),然后执行相应的计算操作。当你执行这些操作时,PyTorch 将会构建计算图,记录下所有的计算步骤,以便之后计算梯度。计算梯度时,你可以调用张量的 backward() 方法,然后梯度将会累积在每个相关的张量的 grad 属性中。
以下是一个简单的示例,演示了如何在 PyTorch 中使用 grad 属性来计算张量的梯度:
import torch x = torch . tensor ( [ 2.0 ] , requires_grad = True ) y = x ** 2 y . backward ( ) print ( x . grad ) 在这个示例中,我们创建了一个张量 x,并计算了函数 y = x 2 y = x^2 y = x 2 y.backward(),PyTorch 计算了关于 x 的梯度,并将梯度值存储在 x 的 grad 属性中。在这种情况下,函数 y = x 2 y = x^2 y = x 2
下面的例子,如何对 y = 2 x T x y = 2x^Tx y = 2 x T x
这里使用 PyTorch 自动求导来计算导数。
首先创建一个变量 X 作为列向量
import torch x = torch . arange ( 4.0 ) x 在我们计算 y y y x x x x x x x x x
x . requires_grad_ ( True ) x . grad 现在计算 y y y
tensor(28., grad_fn=<MulBackward0>) x 是一个长度为 4 的向量,计算 x 和 x 的点积,得到了我们赋值给 y 的标量输出。 接下来,通过调用 反向传播函数 来自动计算 y 关于 x 每个分量的梯度,并打印这些梯度。
tensor([ 0., 4., 8., 12.]) 函数 y = 2 x T x y = 2x^Tx y = 2 x T x 4 x 4x 4 x
tensor([True, True, True, True]) References