时间复杂度分析
研究算法的最终目的就是如何花更少的时间,占用更小的内存去完成相同的需求,因此需要对算法进行分析
函数的渐近式增长
看书的 p27-p29 页可以总结以下规律
算法函数中 n 最高次幂越小,算法效率越高
1、算法函数中的常数可以忽略 2、算法函数中最高次幂的常数因子可以忽略 3、算法函数中最高次幂越小,算法效率越高
算法时间复杂度定义
就是让执行次数 = 执行时间
在进行算法分析时,语句总的执行次数 T(n) 是关于问题规模 n 的函数,进而分析 T(n) 随 n 的变化情况并确定 T(n) 的数量级。算法的时间复杂度,也就是算法的时间量度,记作:T(n) = O(f(n))。它表示随问题规模 n 的增大,算法执行时间的增长率和 f(n) 的增长率相同,称作算法的渐近时间复杂度(其中 f(n) 是问题规模 n 的某个函数)
注意:时间复杂度是按照该算法 最坏的情况 算的,同时大 O 记号并不直接表现算法的执行时间,而是指代码执行时间 随着输入数据的增长而变化的趋势,所以也叫作渐进时间复杂度。
就是把核心操作的次数和输入规模关联起来

这种以 O() 来体现算法复杂度的记法称之为 大 O 记法
推导大 O 阶的方法:
1、用常数 1 取代运行时间中的所有加法常数 2、在修改后的运行次数函数中,只保留最高阶项 3、如果最高阶项存在且不是 1,则去除与这个项相乘的常数
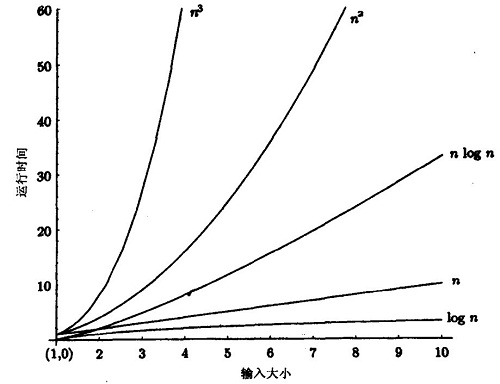
补充:对数函数是如何变化的,放两张图方便快速回忆:
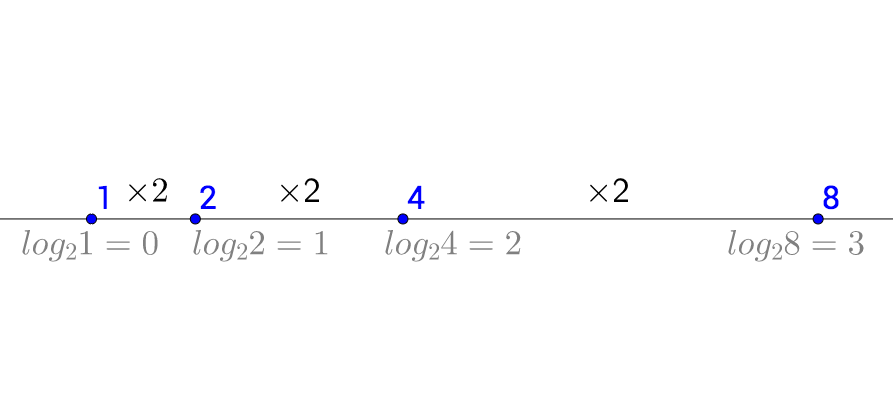

线性阶
public static void main(String[] args) {
int sum = 0;
int n = 100;
for (int i = 1; i <= n; i++) {
sum += i;
}
System.out.println("sum=" + sum);
}
就是
平方阶
public static void main(String[] args) {
int sum = 0;
int n = 100;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
sum += i;
}
}
System.out.println("sum=" + sum);
}
一般就是嵌套循环
对数阶
public static void main(String[] args) {
int count = 1;
while (count < n) {
count = count * 2;
}
System.out.println("count =" + count);
}
如上代码,由于 得 所以这个时间复杂度为 (注意这里的底数 2被省略了)
常见的时间复杂度总结
| 描述 | 增长数量级 | 说明 | 举例 |
|---|---|---|---|
| 常数级别 | 1 | 普通 | 将两个数相加 |
| 对数级别 | logN | 二分策略 | 二分查找 |
| 常数级别 | N | 循环 | 找出最大元素 |
| 线性对数级别 | NlogN | 分治思想 | 归并排序 |
| 平方级别 | N^2 | 双层循环 | 检查所有元素对 |
| 立方级别 | N^3 | 三层循环 | 检查所有三元组 |
| 指数级别 | 2^N | 穷举查找 | 检查所有子集 |

函数调用的时间复杂度分析
前面分析的都是单个函数内的时间复杂度,但是有需要分析函数调用过程中的时间复杂度
案例一
public static void main(String[] args) {
int n = 100;
for (int i = 1; i <= n; i++) {
show(i);
}
}
private static void show(int i) {
System.out.println(i);
}
由于这个 show 方法内部只执行了一行代码,所以 show 方法的时间复杂度为 ,那 main 方法的时间复杂度就是
案例二
public static void main(String[] args) {
int n = 100;
for (int i = 1; i <= n; i++) {
show(i);
}
}
private static void show(int i) {
for (int j = 1; j <= n; j++) {
System.out.println(i);
}
}
在 main 方法中有一个 for 循环,show 里面也有一个 for 循环,所以时间复杂度为
递归的时间复杂度(Master 公式)
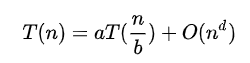
- a 代表 子问题是等规模的情况下,调用了多少次
- 后面的 代表除去调用子过程之外,剩下过程的时间复杂度
- 而 代表子问题的规模
举例:
求数组中的最大值
public static int getMax(int[] arr) {
return process(arr, 0, arr.length - 1);
}
public static int process(int[] arr, int L, int R) {
// base case
if (L == R) return arr[L]; // arr[L..R] 范围上只有一个数,直接返回
int mid = L + ((R - L) >> 1); // 中点
int leftMax = process(arr, L, mid);
int rightMax = process(arr, mid + 1, R);
return Math.max(leftMax, rightMax);
}
可以看到这里的 process 递归方法每次调用了两次,所以 a = 2 而每次都是求中点开始求,所以每次的子问题规模都是 = 而抛开子问题的调用,其它的步骤都是常量级的,所以 = (所以 d 等于 0)
最后套入公式:
注意:Master 公式得保证每个子问题是等规模的(例如上面的,第一个规模为 n/3 第二个规模为 2 * n/3 这种就不行)
取得 a、b、d 然后再根据下面这个图里的条件判断,最后可以得出右边的时间复杂度

上面那个例子满足第三条,因此时间复杂度为: